Running a web host is great fun. It requires expert tech skills, a real passion for learning, and a liking for people. But it also requires some hefty investigation and journalism skills too; not every answer can be had from Google and ChatGPT!
What happened?
Over the past few weeks we’ve had waves of abusive traffic hit our managed customer servers in the form of heavy web crawls, ignoring robots.txt, POSTing garbage to forms and so on. This in itself isn’t unusual, which is why we have software to analyze logs and detect potentially abusive IPs/subnets, then rate-limit or block accordingly. We also have a central logstore which aggregates log data and collectively shows the heaviest abusing IPs, most frequent requests, most targeted CMS’ etc, and we block the heaviest abusers at network edge.
Our first reaction – block all the things!
We’re a true 24x7x365 company with techs on duty day-and-night to deal with events like these. Sadly they’re not uncommon, and we encounter perhaps 2-3 events like this per year, where new proxy networks crop up and wreck havoc. In traffic abuse cases, our standard action is to WHOIS lookup the abusive IP’s owner, because often the network name is enough for us to understand the what traffic actually is. We’ll then block a single /32 IPv4 if there’s just one misbehaving, maybe a handful of IPs if it seems to be a smaller ISP-provided prefix, or the /24 (or advertised prefix length) if the traffic is from many IPs. In the worst of cases, we blackhole the entire ASN at edge.
Analyze the traffic & hotfix the code
Once we get the abusive traffic blocked and the customer’s server recovered, we’ll do some further analysis on the traffic to see whether there’s anything in common we can block. We might find something unique in the referrer, user agent, perhaps a query string and so forth. If we find something obvious, for example if a particular set of HTTP forms are being abused, or a crawler is going HAM on ecommerce product filters, we’ll write some Apache/Nginx rules to either limit the traffic or flag it with a response code that we can use to block the IP further down in the stack. Sometimes we find heavy CMS websites with caching disabled or misconfigured, so we’ll setup CMS caches or forced server-side caching at this point too.
This traffic was unique
Our techs analyzed the abusive traffic, but found the requests had very little in common. They originated from thousands of unique IPs, spread out over tens of ASNs, and identified with different headers on almost every request. There was even a fair mix of illegitimate residential IP traffic too, denoted by the lack of requests for supporting image, CSS and JS files. However, there was one name that kept cropping up in IP WHOIS and ASNs: code200.
Whatever this thing is, it’s built to purposefully evade automated limiting tools and generate as much traffic as possible. Since there’s no unique pattern to be identified, it slipped through our software and caused high resource consumption on customer servers, which impacted the performance of websites until our team could whack a block/fix.
What’s code200?
Great question! Our techs seemingly do not possess the same investigative skills I do, so their searches drew blanks and they gave up. But as I sat in a hospital bed, in pain, on a drip, I dug deeper. Here’s what I found:
- I Googled ‘Code200 UAB’ which gave a few fraud/spam/scam IP reputation sites, so the VPN/proxy alarm bells started ringing. Scamalytics has a list of companies/brands it thinks are related to Code200 UAB on this [bak] page, which is interesting but probably a red herring.
- Google also gave www.code200.global [bak], who claim to sell everything from end-user internet access to cloud compute and even IT consultancy. Their website lacks any coverage areas or countries, has no shopping cart, login/registration form doesn’t work, and shows no company registration or contact info. It’s proxied by Cloudflare and MX shows Google Workspace, so nothing helpful.
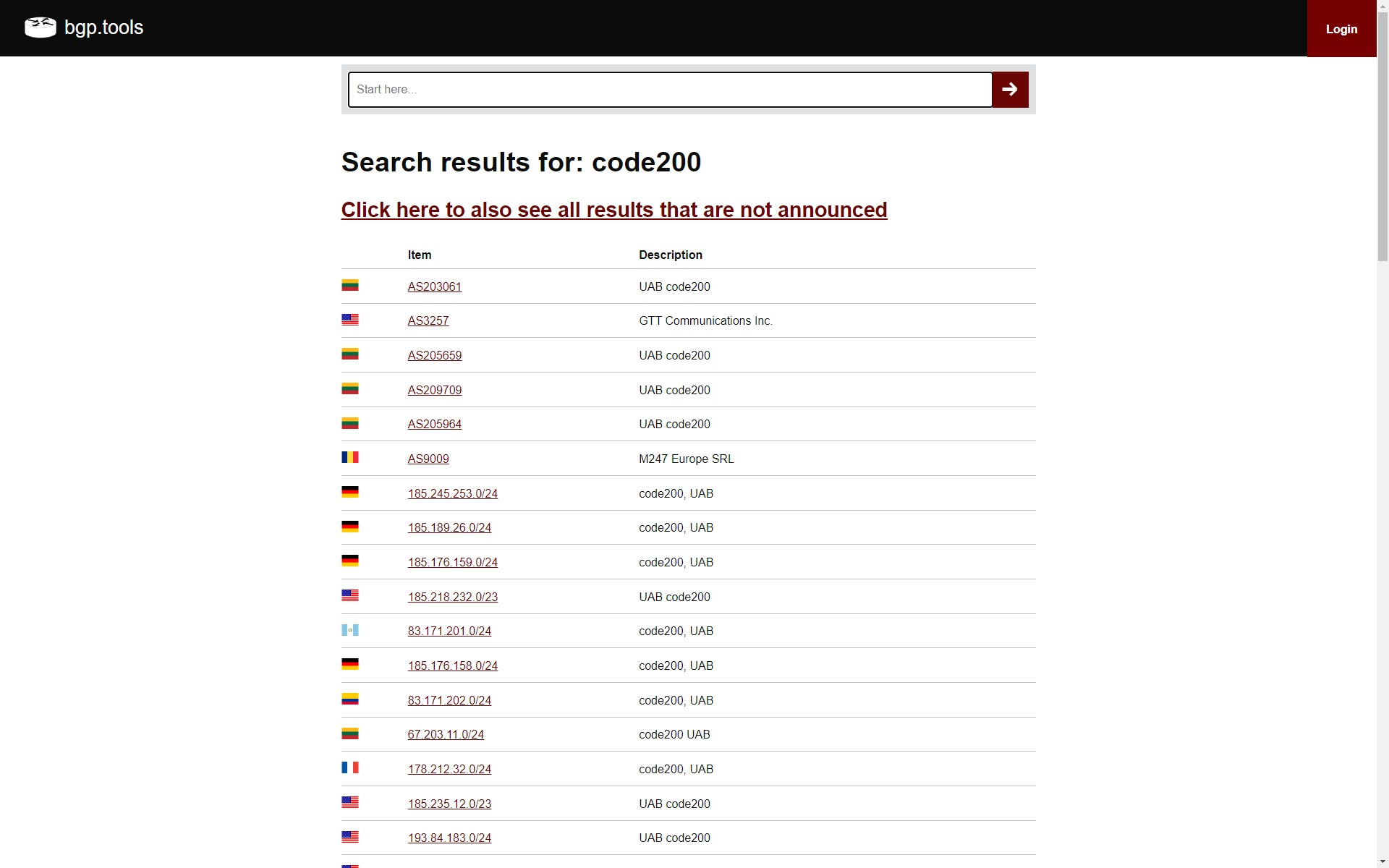
- I searched BGP.tools [bak] for some of the prefixes, which gave me Code200, Code200 UAB, Cogent (lol) and some other well-known cesspit ISPs. There were a few ASNs named and registered under Code200 directly, but many prefixes were advertised by other ASNs. Again, VPN/proxy alarm bells.
- I then Googled ‘Code200 UAB proxy’ and found a link to this [bak] PDF from brightdata.com. It’s a demand for a patent infringement court case against Code200 UAB. On the first page, under The Parties, read 2.
Who’s Corenet, Metacluster, Teso & Oxysales?
Another good question! At least we have some solid data to go off now.
- All of these companies are registered in Lithuania.
- They share the same physical address and same directors/owners as per Bright Data.
- Searching Corenet (+ UAB) gives no useful information.
- Searching Metacluster (+ UAB) gives us no website or brand, however we see they’ve filed for 3 patents, they’re actively disputing a fourth, and have been sued for infringement of another.
- Searching Teso (+ LT, UAB) gives us a few indirect linkbacks to tesonet.com. More on Tesonet later…
- Searching Oxysales (+ UAB) gives us https://oxylabs.drift.click which links to https://oxylabs.io. Finally, some actual progress!
What about Code200.io?
I Googled ‘code200 seo’ and found www.code200.io, [bak] an SEO company. Their website looks like a straight up “import demo data” from a ThemeForest SEO template, with a tacky logo designed in Paint. They do have some genuine case studies dating back to 2020, so somebody is putting in the work. It’s interesting that their work is focussed on SaaS startups, as that’s an area Tesonet also focus on.
According to code200.io’s website they’re based in Ukraine, although no address is given. They’re hosted by OVH and in BHS of all places, which is an odd choice for a Ukrainian company. Their MX is Google, and NS hosted by “Hosting Ukraine Ltd” of AS200000 (nice!). AS200000 doesn’t have any prefixes belonging to the Tesonet lot, doesn’t share any weird upstreams, and seems to be the legitimate www.ukraine.com.ua’s ASN.
I think code200.io are an innocent bystander who chose their name because, with the shady show Code200 UAB are running, code200.global either didn’t exist or was throwing blanks at the time they searched.
What’s Oxysales and Oxylabs.io?
It’s clear from backlinks, trading names and addresses that these are one in the same company. They sell Residential Proxies, Mobile Proxies, Datacenter Proxies, and Scraper APIs.
Residential and Mobile proxies are, I presume, where end-users install Oxylabs software onto their devices and get paid for the traffic they relay. Datacenter proxies we’ve already seen, hence how we got here in the first place. But the thing we’re interested in the most is the Scraper API product, and their new Web Unblocker.
What’s Scraper API?
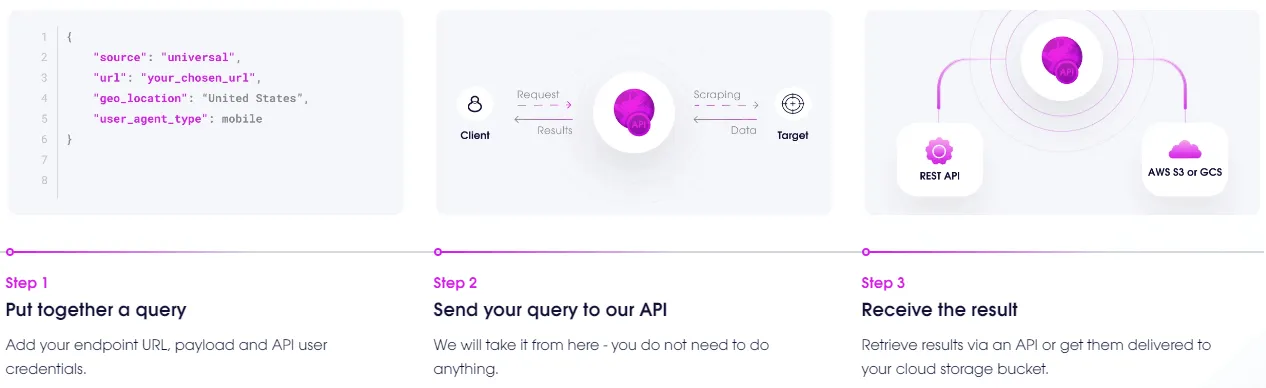

Apparently Scraper API works by submitting a location, starting URL, set of keywords and user agent type, then the API does crawling of any linked and related websites automatically. This is interesting, because typical proxy-based SEO services give you a proxy URL for software running on your local computer, and your own software & computer generates the requests. This is the opposite, and in fact, you only submit a single API request. You don’t need any processing power or bandwidth, just somewhere to store the results.
What’s Web Unblocker?

When I check our logs of these heavy crawls, I see a distinct pattern that matches Web Unblocker’s behaviour. In particular, on the odd occasion our server-side software identifies and rate-limits an abusive IP address, I see the same request come in from a different IP a few seconds later. This doesn’t happen with successful requests from IPs that aren’t rate-limited.
How do companies get residential IPs?
There are three ways:
Pretend with ‘fake’ residential IPs
Use existing data centre prefixes, map PTR (reverse DNS) records to domains that look like they’re residential ISPs, register pseudo companies that pretend to offer residential connections, then throw a website together to support such perception.
An example is ‘amsterdamresidential.com’ which belongs to VPN company Private Internet Access. They use this domain to pretend their VPN endpoints are in Amsterdam to evade copyright laws, and trick streaming services & location checkers so users can access country-locked services.
Another example is, of course, our dear friends at www.code200.global.
Pay-to-proxy end user schemes
Proxy companies write software for installation onto legitimate end-user devices, then pay end-users a fee for traffic that is proxied through their connection. This way, the traffic looks genuine to the target host/site because it’s mixed with 100% real end user traffic. If there’s enough participants, this can be a real problem for the host/server, and might require forced captcha/bot/javascript challenges to weed out the illegitimate requests.
Malware-installed proxy software
Where there’s a will to make money, there’s a way to exploit. It’s common for malware to install software onto infected devices, which can include crypto miners and proxies. The latter is the most problematic traffic source of all, because at low traffic volumes, the end-user might never know their device is participating in a proxy network, and it might take years for the software to be detected and removed from the end-user’s device.
Who’s Teso and Tesonet?
Teso and Tesonet are one in the same; I’d imagine they renamed due to the lawsuits from Bright Data. Tesonet owns – or at least heavily invests in – tech-focussed companies including the hosting company Hostinger, VPN companies Nord, Surfshark and atlasVPN, as well as various tech, bio-tech and AI companies. They also have Šiaulių Bankas, the third largest bank in Lithuania, on their portfolio. Plus, of course, Oxylabs.
It’s interesting that their portfolio includes VPN companies as well as proxies, because VPNs will greatly improve a ‘poor’ proxy IP reputation. You know when you’re randomly hit with a captcha request, you complete it correctly, then you don’t see another captcha for weeks or months? That’s because you’ve built up some IP reputation and trust with the captcha provider. Therefore, if you’re a VPN user and you complete a captcha successfully, this earns the VPN’s IP some trust. If you’re also running proxy traffic through the same VPN IP – which is entirely possible by the way – it’s a surefire way to get a better IP reputation so that your crawls complete successfully.
Who’s responsible for the traffic?
At this point, I’m sure the traffic is generated by Oxylabs and fine-tuned by their Web Unblocker solution. What I don’t know is who is making the API calls; it could be Oxylabs themselves trying to build up a large indexable database of the web, or it could be one of their customers. I know that whomever it is has a hefty pocket, because these proxy prices ain’t cheap!
I do wonder if other web hosts are seeing the same kind of traffic, and if so, how they’re coping with it? I’ve clocked some performance wobbles at 20i, Krystal and ionos recently so I wonder if they’re being hammered too? Unfortunately I haven’t got many competitor relationships to ask the question. I’d appreciate any feedback!
What’s the short-term solution?
Block all of Code200’s datacentre-based ASNs and prefixes. You can use BGP.tools search to list most, and check your server logs for the other non-WHOIS’d ones.
Even with Oxylabs’ Web Unblocker service, they always seem to start a crawl from their data centre IPs, so if you block these, they can’t get to your website.
Oxylabs report 102 million+ IPs in their roster, 20 million of which being mobiles apparently, which I highly doubt. If we take a look at lists of their BGP-advertised prefixes, we see some familiar names that we’ve encountered in the past, including Aventice and trafficforce. Oxylabs also lease prefixes from well-established hosts including Worldstream, EGIHosting and Zappie Host. This matches our logs, and if Code200 continue leasing more prefixes and using residential IPs, it’ll be much harder to identify and block their traffic in future.
What’s the long-term solution?
I don’t know.
It’s never a good idea to point-blank blackhole traffic, especially not from leased prefixes, and certainly not from genuine eyeball (residential) ISPs! We don’t want to block legitimate users; that’s pretty much the definition of a sucky host. But at the same time, we can’t allow users, services or ISPs to cause abuse that degrades performance or availability, because that’s also the definition of a sucky host.
Should we force-enable captcha/bot/javascript challenges on all managed servers? Such solution would cost a lot of time and money to develop, and it might take a while to get right; think of the false-positives and problems it’d cause! Then, how would we manage reverse-proxy services and CDNs such as Cloudflare and Fastly? We’d need to whitelist all reverse-proxy and CDN prefixes for proxy header passthrough, but lots of end-users would unexpectedly see annoying challenges if we missed a prefix and/or when the provider adds a new one. Then there’s mobile and CGNAT…
What about our customers that aren’t managed; they benefit from our network-wide blocking, but if we a develop a web server module or reverse-proxy solution to do captcha/bot/javascript challenges, they’ll lose out. Sure some hosts would consider this as an upsell possibility, but that sucks, right?
And for the “just use Cloudflare” crowd; no, that’s not possible. Remember, it’s our end-users – predominantly digital agencies and eCommerce customers – that create Cloudflare accounts, and as a web host we have no access to those accounts. Cloudflare’s default security settings will not block or challenge any traffic, even when they know it’s outright abusive, and we can’t access customer accounts to turn on the challenge. In actuality, Cloudflare makes our job even harder, because we need to block the traffic at L7 in software as it hits the final web server. So yeah, thanks Cloudflare.
Are website scraper and big data companies a good thing?
I don’t know enough about the SEO or marketing world to make a judgement. I do question the fairness of a company paying for hundreds of hours of SEO and marketing work, only to have it scraped, duplicated and devalued by their competitors though.
From a web host’s standpoint, I must insist that every crawler, scraper, proxy etc follows robots.txt to the letter, and has sane maximum limits enforced. I appreciate the “pay more for faster results” model, but it’s preferable to hard-cap rather than knowingly allow your users to take down websites or entire servers. “You should have better caching” or “you should upgrade your hosting plan” aren’t valid excuses because the perpetrator will only crawl faster!
Should there be a new (international) law proposal that ensures all crawlers adhere to robots.txt limits? I think so. I’m not sure what other solutions we have. Thoughts?


{kind=link}
{kind=link}
0 Comments